Studie bestätigt: GPT-4 ist der beste KI-Assistent!
Es gibt zahlreiche kommerzielle Angebote und Open-Source-Modelle für generative Text-KIs. Ein speziell für Assistenzaufgaben entwickelter Benchmark zeigt nun, dass GPT-4 in diesem Segment herausragt.
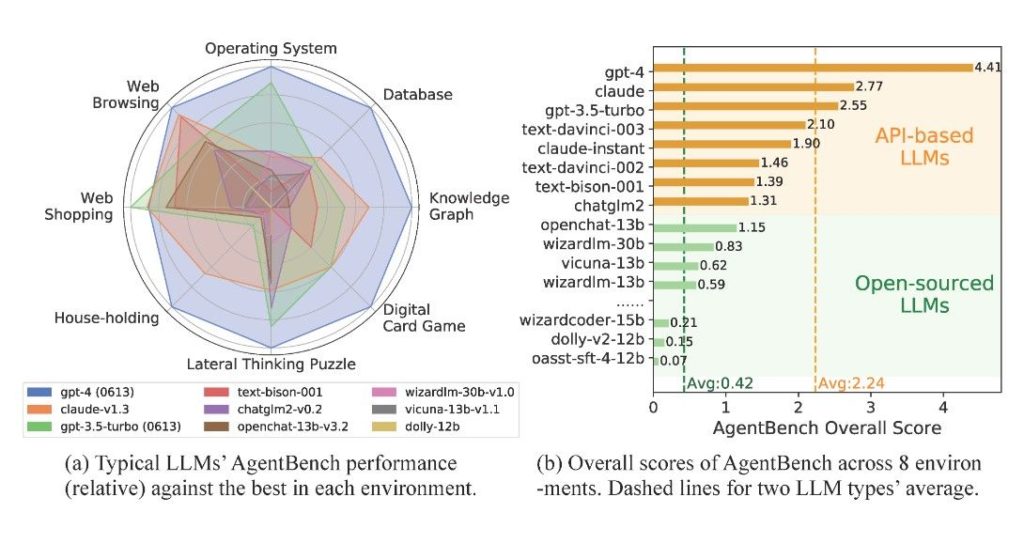
📊 „AgentBench“ ist ein Test für Assistenzaufgaben von Sprachmodellen, der 8 Alltagsbereiche abdeckt. 🏆 GPT-4 erreichte die höchste Punktzahl von 4,41 in fast allen getesteten Bereichen. 📝 Das Forscherteam testete insgesamt 25 Sprachmodelle, darunter kommerzielle und Open-Source-Modelle. 🔄 OpenAIs GPT-4 übertraf in fast allen Disziplinen die Konkurrenz, außer in der Aufgabe „Web-Shopping“. 📈 Open-Source-Modelle hatten eine durchschnittliche Punktzahl von nur 0,42 und versagten oft bei komplexen Aufgaben. 🛠️ Das Forschungsteam stellt Toolkit, Datensätze und Benchmark-Umgebung über GitHub zur Verfügung, um zukünftige Leistungsvergleiche zu ermöglichen.
Nutze KI als Motor für Deine Marketingerfolge
Gewinne mit gezielter KI-Strategie einen entscheidenden Vorteil im Wettbewerb.